
Due to the diversity and large number of Indigenous languages in the Americas, identifying indigenous-language place names is difficult. I hypothesize it will be easier task to identify European place names. We can assume by identifying and setting aside European names in the Americas - most of which are in Spanish, English, French, and Portuguese - the vast majority of remaining place names will be of Indigenous origin.
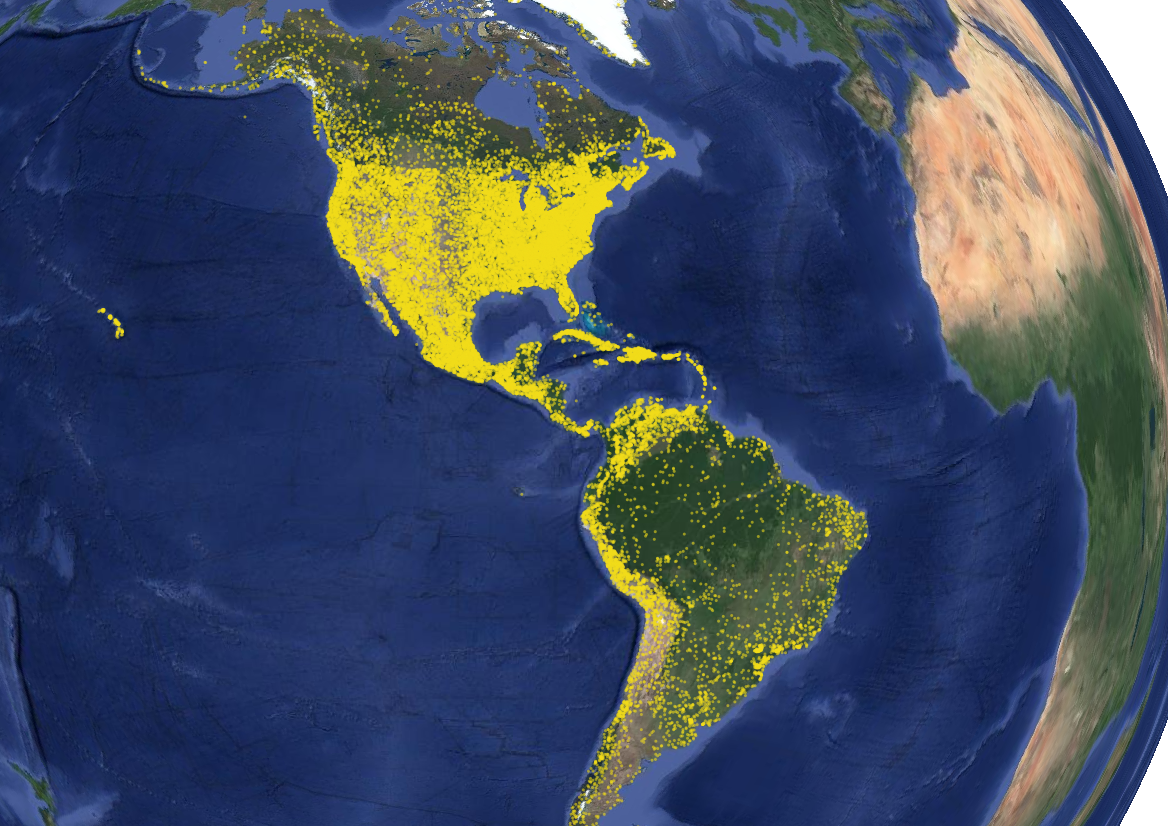
There are several ways to identify European place names. For languages such as Spanish, I hypothesized that a search for Spanish definite articles (la, el, las, los) and common religious titles (san, santa) would allow for the identification of many Spanish place names. To some extent this hypothesis was correct, as the map to the right makes clear. The greatest concentration of locations on this map are in areas that were once part of Spanish America, which once stretched from the southwestern part of what is now the U.S. to Patagonia.
However, the French also use the feminine article "la" and the Portuguese also refer to female saints as "santa." These two words - the French "la" and the Portuguese "saint" explain the concentrations of such locations in Quebec, the Mississippi Valley, and Brazil. Other anomalistic spatial patterns are the result of unique historical circumstances or modern corporate expansion. For the former, in the northwestern-most corner of the U.S. the explorer Francisco de Eliza named a group of islands between Vancouver Island and present-day Seattle "San Juan." For the latter, many places in the interior of the U.S. Northwest are actually La Quinta Inns. Obviously, I need to subset out modern business names from the GeoNames database.
